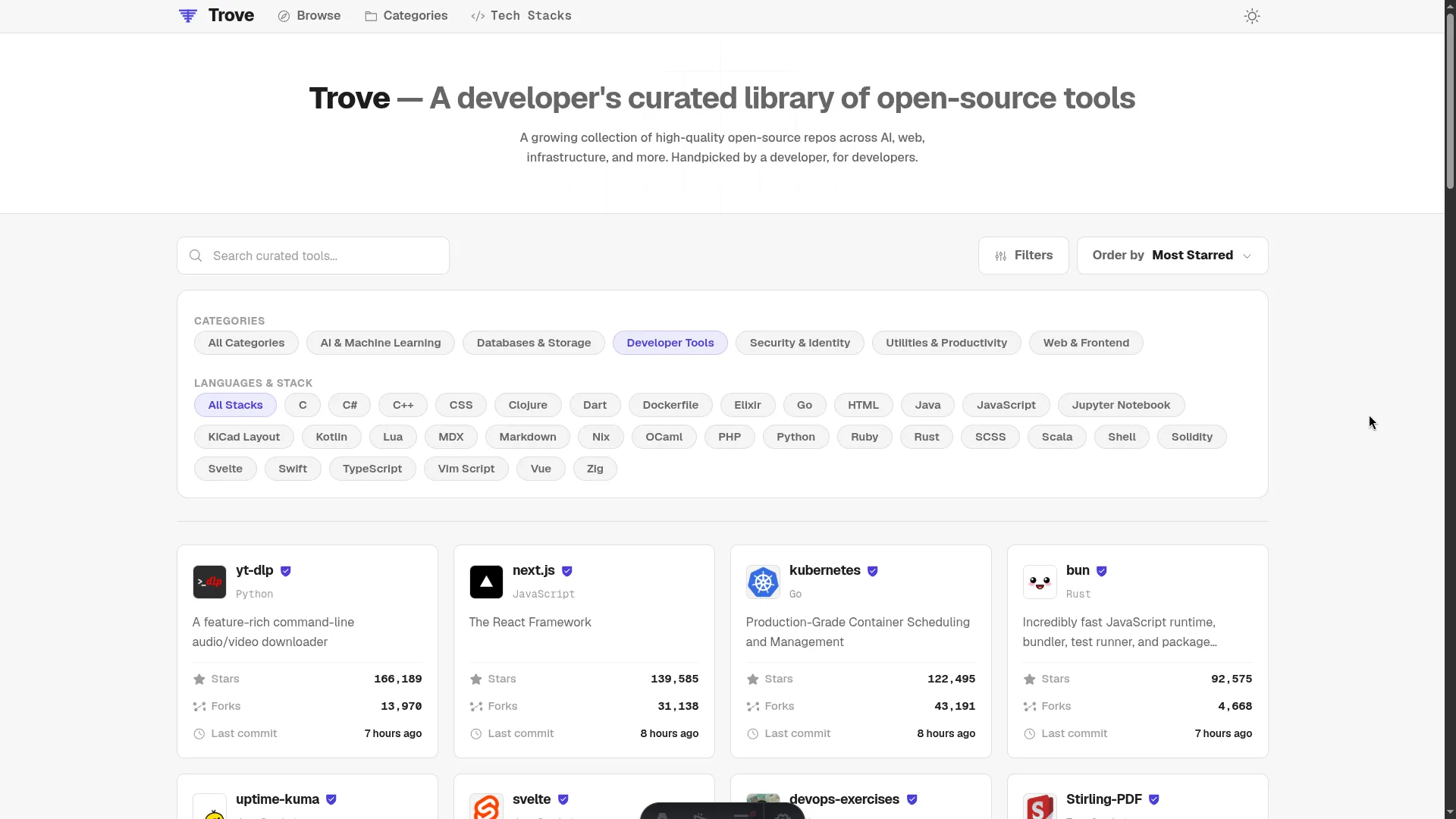
Trove: Personal Curated GitHub Repos
A developer-curated directory of 1,200+ production-ready open-source libraries, devtools, and alternatives handpicked directly from developer stars.






🎯 Project Overview
Trove is a high-density, developer-first web directory showcasing over 1,200+ production-ready open-source libraries, developer tools, and software alternatives. Instead of browsing scattered GitHub stars or heavily monetized/sponsored alternative directories, Trove provides a clean, zero-fluff discovery engine handpicked directly from developer stars.
🏛️ Technical Architecture
Trove is built using a hybrid performance architecture that combines static site generation with dynamic client-side hydration:
- Astro Static Engine: The directory pre-renders 1,229+ repository detail pages (
/gem/[slug]) during the build phase. This leverages a local structured JSON database (github_stars.json), ensuring zero database connection overhead or latency during runtime navigation. - Dynamic Client-Side README Parsing: To prevent static bundle bloating (pre-rendering 1,200+ full-length READMEs would result in multi-megabyte HTML files), README content is fetched directly from the raw GitHub user content CDN (
raw.githubusercontent.com) at runtime. - 100% GitHub-Flavored Markdown (GFM) Compatibility: The fetched raw markdown text is parsed dynamically using
marked.js. Custom global CSS overrides manage tables, task lists, nested bullet points, inline code styling, responsive iframe embeds, and contributor image wrapping.
🧠 Core Philosophy & Ideology
Trove was born out of a clear frustration with the modern developer resource ecosystem. When looking for open-source alternatives, libraries, or devtools, developers are typically faced with two sub-optimal choices:
- Generic Crowdsourced Lists: Platforms like OpenAlternative are highly useful but suffer from public submission spam, outdated listings, or search engine optimization (SEO) bait where low-quality, sponsored, or semi-abandoned tools are pushed to the top.
- Unstructured Awesome-Lists: Massive curated markdown files on GitHub (e.g.,
awesome-react,awesome-go) contain high-quality entries but lack sorting, search indexing, responsive layout structures, and instant filtering capabilities.
Trove bridges this gap by acting as a developer's curated treasure vault. Every single one of the 1,200+ entries is sourced directly from a developer's active GitHub stars. This guarantees a high-signal catalog of production-tested utilities, developer tools, SaaS alternatives, learning primers, and AI agent frameworks.
💡 The "Why" Behind Trove
The primary reasons for creating Trove include:
- Curating Beyond "SaaS Replacements": While listing alternatives to popular software like Slack or Notion is valuable, developers need a deeper repository of core infrastructure blocks—such as lightweight database ORMs, state management systems, performant CLI builders, custom router packages, and specialized WebAssembly compilers.
- Signal Over Noise: Every repository listed in Trove has been vetted for activity, community adoption, and architectural elegance. There is no pay-to-play model or sponsored listing space; the database is purely meritocratic and utility-focused.
- The High-Density Bento System: Modern web design often favors excessively large whitespace margins, forcing developers to scroll continuously to find information. Trove's layout uses a high-density, bento-grid approach (up to 4 columns on desktop with compact grid margins) to deliver maximum information density per pixel, matching the productivity standards expected by engineers.
- Millisecond Loading Speed: Built on a zero-database-runtime architecture, the entire directory compiles statically. Dynamic fetching of readmes ensures the main site bundles remain lightweight and responsive, decoupling the site from potential database scaling bottlenecks or third-party API rate limiting.