SettleVox: AI Voice Legal Intake Agent
Real-time AI voice agent conducting automated legal intake calls — built on WebSockets, Cartesia STT/TTS, Groq LLM, and an 8-phase finite state machine pipeline.















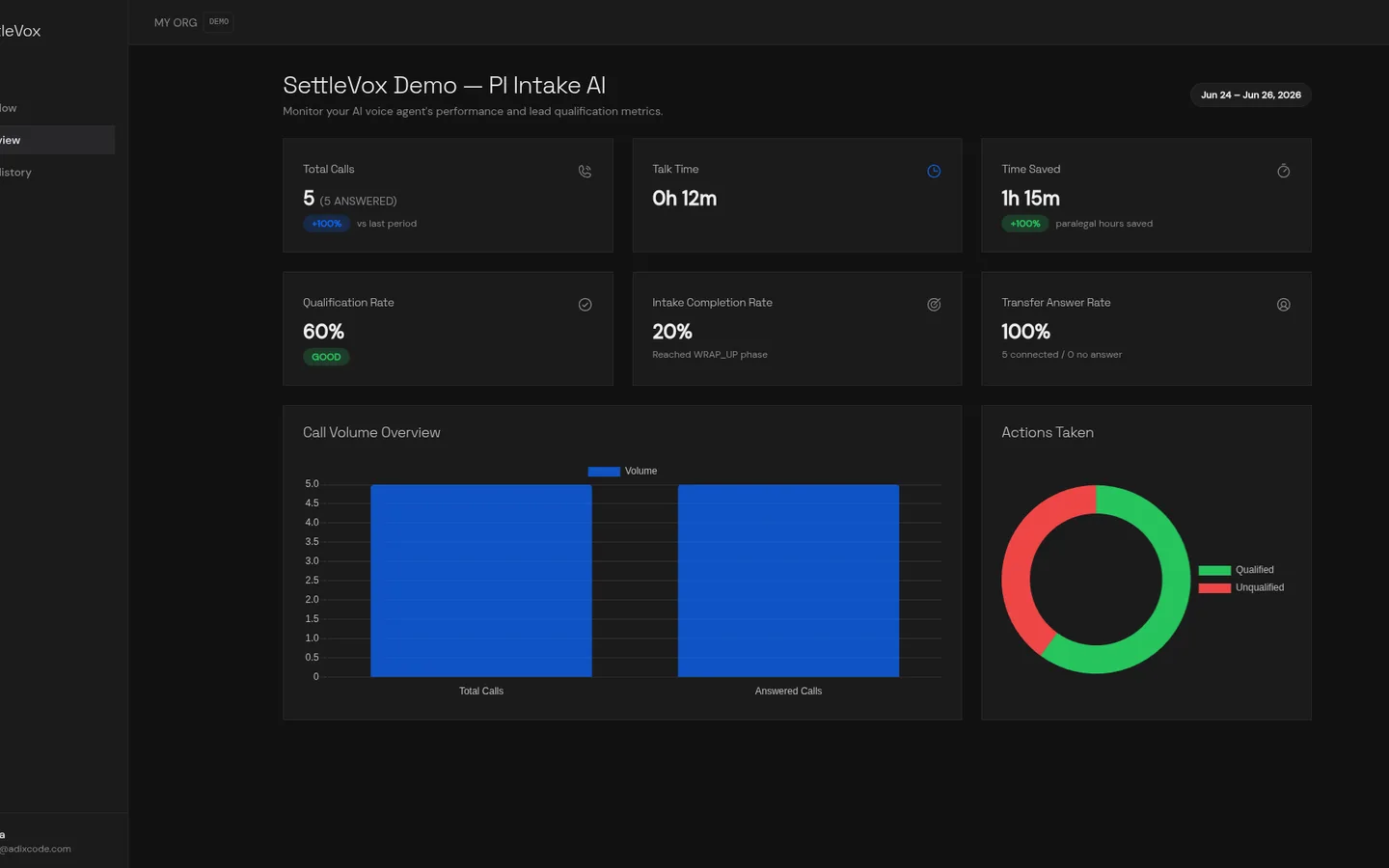
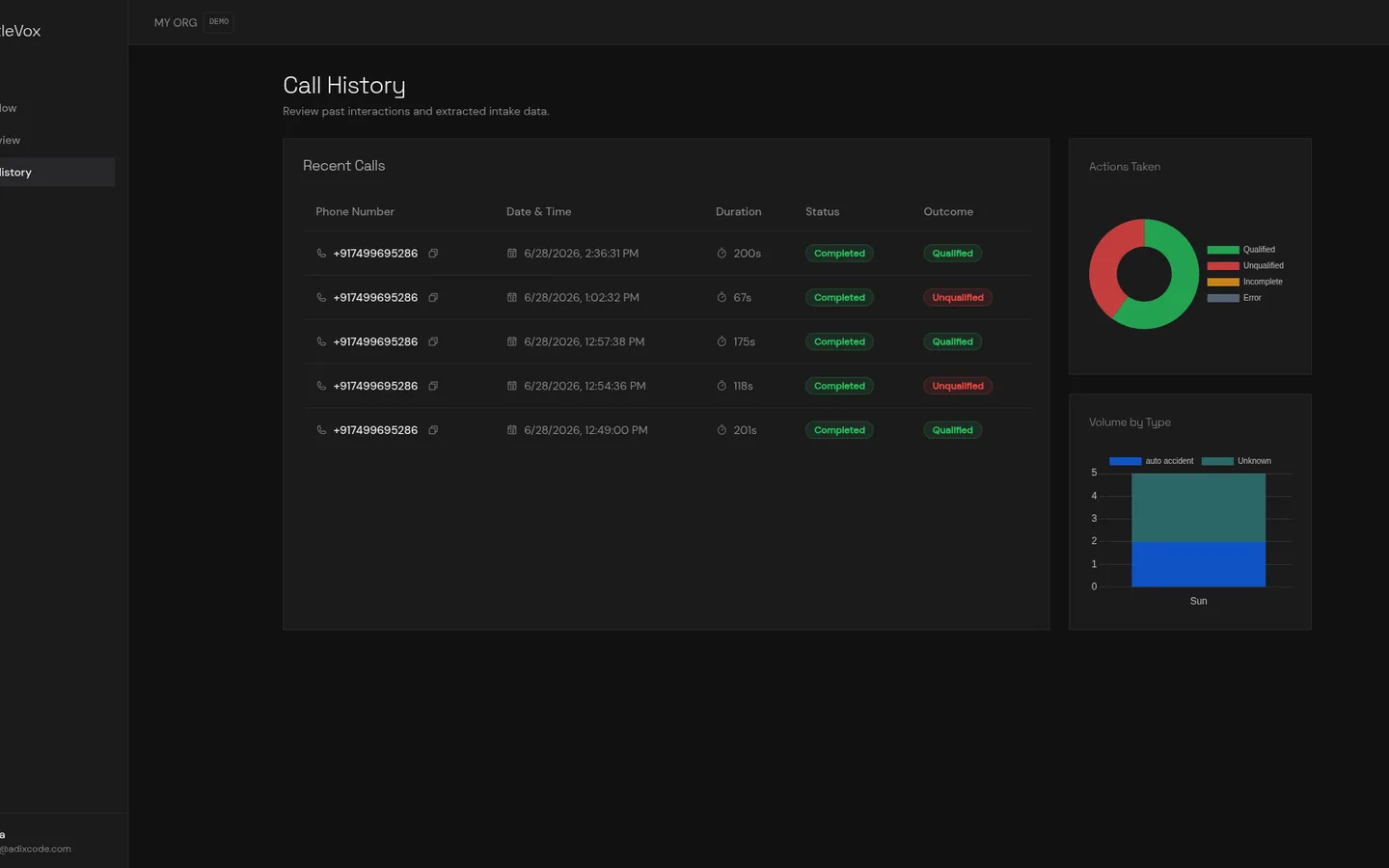
SettleVox is a fully automated voice AI agent designed to replace human intake coordinators at personal injury law firms. When a prospective client calls, SettleVox answers, conducts a structured legal intake interview in natural speech, qualifies or disqualifies the lead in real time, and persists a structured JSON record — all before a human ever picks up the phone.
The Problem
Personal injury law firms receive hundreds of intake calls per week. A significant percentage are from unqualified leads — callers with no third-party liability, no documented injuries, or who refuse consent. Routing these through human coordinators wastes thousands of hours annually.
The challenge: build a voice AI agent that:
- Sounds natural — No robotic TTS delays or uncanny valley responses
- Handles barge-ins — Callers interrupt constantly; the agent must stop mid-sentence and adapt
- Extracts structured data — Names, incident dates, fault assessments must be parsed, not just logged as raw audio
- Enforces legal compliance — TCPA consent must be obtained before recording; no workarounds
Architecture Overview
Key Technical Decisions
The Real-Time Pipeline — No Off-the-Shelf Framework
Most voice AI frameworks (Vapi, Bland) abstract away the pipeline in exchange for control. SettleVox builds every layer from scratch using Node.js WebSockets, EventEmitter, and direct API integrations:
// Orchestrator: the beating heart of the pipeline
export class Orchestrator {
private stt: SpeechToText; // Cartesia Ink-2 via WebSocket
private llm: LLMEngine; // Groq Llama 3.3 70B, streaming
private tts: TextToSpeech; // Cartesia Sonic-3.5 via WebSocket
private fsm: IntakeFSM; // 8-phase deterministic state machine
// Audio comes in from Twilio → decoded → forwarded to Cartesia STT
public receiveAudio(audioBuffer: Buffer) {
this.stt.sendAudio(audioBuffer);
}
}Three separate persistent WebSocket connections run in parallel for the entire call duration — Cartesia STT, Cartesia TTS, and Twilio Media Streams — all orchestrated through a single EventEmitter graph.
Finite State Machine (IntakeFSM) — 8 Deterministic Phases
The agent's conversational flow is governed by a typed FSM — not a giant prompt. This is what makes SettleVox reliable instead of probabilistic:
export const INTAKE_PHASES: Record<PhaseName, Phase> = {
GREETING: { requiredFields: ['consent_given'], next: 'INCIDENT_DETAILS' },
INCIDENT_DETAILS: { requiredFields: ['incident_description', 'incident_date', 'incident_location'], next: 'INJURY_ASSESSMENT' },
INJURY_ASSESSMENT:{ requiredFields: ['injuries_described', 'treatment_status'], next: 'LIABILITY' },
LIABILITY: { requiredFields: ['other_party_involved', 'fault_assessment'], next: 'INSURANCE' },
INSURANCE: { requiredFields: ['insurance_info_available'], next: 'QUALIFICATION' },
QUALIFICATION: { requiredFields: ['is_qualified'], next: 'WRAP_UP' },
DISQUALIFICATION: { requiredFields: ['qualification_reason'], next: null },
WRAP_UP: { requiredFields: ['caller_email'], next: null },
};The FSM fast-tracks automatically: if a caller provides their incident, injuries, and liability status all in one sentence, the LLM extracts all fields simultaneously and the FSM jumps directly to QUALIFICATION, skipping redundant phases.
The <FSM_STATE> Delimiter Protocol — Speech + Extraction in One Stream
Rather than making two separate LLM calls (one for speech, one for JSON extraction), SettleVox uses a custom single-stream protocol. The LLM produces a single response in two parts separated by a delimiter:
"I'm so sorry to hear about your accident. Just to confirm —
you mentioned this happened on June 15th near downtown Chicago?
<FSM_STATE>{"incident_date":"2026-06-15","incident_location":"downtown Chicago"}The Orchestrator's streaming parser emits speech tokens to Cartesia TTS in real time, then parses the JSON block post-stream to update the FSM — all in a single API round-trip. This cuts latency by ~400ms per turn.
Barge-In Detection & Interruption
Callers interrupt agents constantly. SettleVox handles this properly:
private handleInterimTranscript(text: string) {
// Require 2+ words or 5+ chars to prevent echo-cancellation false positives
const words = text.trim().split(/\s+/);
if (words.length >= 2 || text.length > 5) {
this.handleBargeIn();
}
}
private handleBargeIn() {
this.llm.interrupt(); // Abort the active Groq stream
this.tts.interrupt(); // Cancel the active Cartesia TTS context
this.ttsBuffer = ''; // Discard buffered sentences
this.twilioWs.send(JSON.stringify({
event: 'clear', streamSid: this.streamSid // Flush Twilio audio buffer
}));
}All three active streams — LLM generation, TTS audio, and Twilio playback — are cancelled atomically within a single event loop tick.
Multi-Key Rotation — Surviving Rate Limits Under Load
At peak hours, a single API key exhausts Groq's free tier in minutes. SettleVox supports unlimited key rotation:
// Load up to 50 Groq keys from env: GROQ_KEY_1, GROQ_KEY_2, ... GROQ_KEY_N
for (let i = 1; i <= 50; i++) {
const key = process.env[`GROQ_KEY_${i}`];
if (key && !GROQ_KEYS.includes(key)) GROQ_KEYS.push(key);
}
// Permanently blacklist keys blocked at org level (model_permission_blocked_org)
private rotateGroqKey(blacklistCurrent = false) {
if (blacklistCurrent) GROQ_BLACKLISTED.add(activeGroqIndex);
activeGroqIndex = (activeGroqIndex + 1) % GROQ_KEYS.length;
}Rate limit errors trigger a key rotation with a 500ms backoff. Org-level model blocks are permanently blacklisted so they're never retried. This keeps 100% uptime across concurrent calls without a paid API tier.
Sentence-Level TTS Chunking — Sub-200ms First Audio
Instead of waiting for the full LLM response before speaking, SettleVox pipes each grammatically complete sentence to Cartesia the moment it's available:
private handleLLMChunk(chunk: string) {
this.ttsBuffer += chunk;
// Split on sentence-terminal punctuation: "." "?" "!" followed by whitespace
let match = this.ttsBuffer.match(/[.?!]\s/);
while (match && match.index !== undefined) {
const sentence = this.ttsBuffer.substring(0, match.index + match[0].length);
this.ttsBuffer = this.ttsBuffer.substring(match.index + match[0].length);
// continue: true keeps the same TTS context for prosody continuity
this.tts.sendText(sentence, this.currentContextId, true);
match = this.ttsBuffer.match(/[.?!]\s/);
}
}Cartesia's continue: true flag keeps all sentence chunks in the same audio context, preserving prosody and natural rhythm across sentence boundaries.
TCPA Compliance — Consent-First Architecture
SettleVox enforces TCPA compliance at the FSM level, not the prompt level. If a caller refuses recording consent, the FSM immediately transitions to DISQUALIFICATION and the entire intake pipeline halts — the agent cannot accidentally continue:
if (extractedData.consent_given === false || extractedData.consent_given === 'REFUSED') {
this.extractedData.qualification_reason = 'consent_refused';
this.currentPhase = 'DISQUALIFICATION'; // Hard stop — no override possible
}Feature Set
| Feature | Implementation |
|---|---|
| Live Voice Calls | Twilio → WebSocket → Orchestrator pipeline |
| Speech-to-Text | Cartesia Ink-2 AutoFinalize (real-time turn detection) |
| LLM Brain | Groq Llama 3.3 70B with streaming + key rotation |
| Text-to-Speech | Cartesia Sonic-3.5 with sentence-level chunking |
| Barge-In | Atomic interruption of LLM + TTS + Twilio buffer |
| 8-Phase FSM | Deterministic intake flow with fast-forward logic |
| TCPA Guardrails | FSM-level consent enforcement, not prompt-level |
| Zod Schema | Typed extraction with REFUSED/UNKNOWN fallbacks |
| AI Summary | Post-call sentiment analysis + 1-sentence summary |
| SSE Dashboard | Real-time call status push to React CRM frontend |
| Multi-Key Pool | Up to 50 Groq keys with permanent blacklist logic |
| Click-to-Talk | Demo portal triggers outbound call via Twilio REST |
Demo Scenarios
The SettleVox live demo supports six edge case scenarios to verify the robustness of the FSM and pipeline:
| # | Scenario | What It Tests |
|---|---|---|
| 1 | Golden Path | Full auto accident intake — qualification + wrap-up |
| 2 | Unqualified Lead | No third-party liability → fast-track disqualification |
| 3 | Barge-In | Interrupt agent mid-sentence → instant stream abort |
| 4 | Over-Sharer | All data in one breath → FSM auto-advances phases |
| 5 | Contact Refusal | Refuses name/email → Zod logs as REFUSED, continues |
| 6 | TCPA Refusal | Refuses recording consent → immediate pipeline halt |
What I Learned
Building SettleVox revealed that the hard part of voice AI isn't the LLM — it's the real-time audio plumbing. Managing three simultaneous WebSocket connections with sub-50ms event propagation, handling TCP backpressure on 8kHz µ-law streams, and atomically cancelling in-flight API calls during barge-ins requires careful EventEmitter architecture.
The <FSM_STATE> delimiter protocol was the key insight: by encoding both speech and structured data into a single LLM stream, I eliminated an entire round-trip API call per conversational turn — making the agent feel genuinely fast and natural rather than AI-laggy.