JEMS: Job Exploration & Matching System
LLM-powered job search intelligence platform with web scrapers ingesting 100K+ listings, a fine-tuned AI matching engine, and a real-time chat interface.














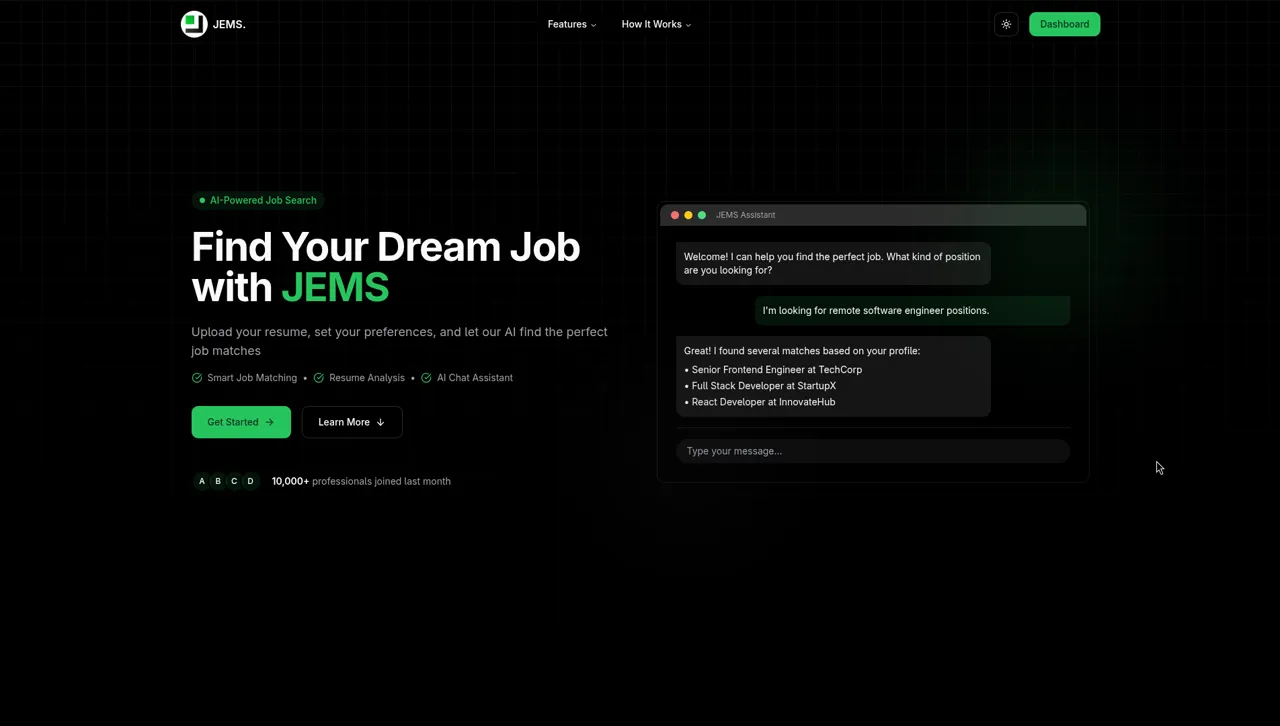
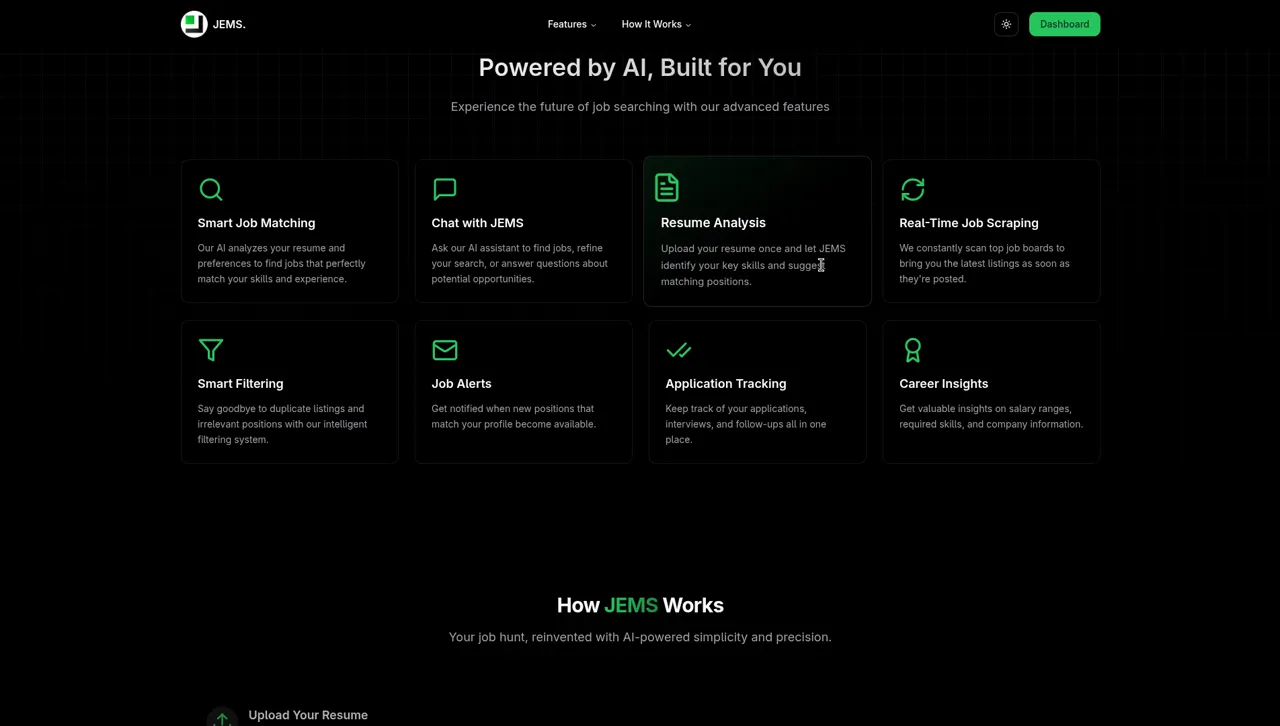
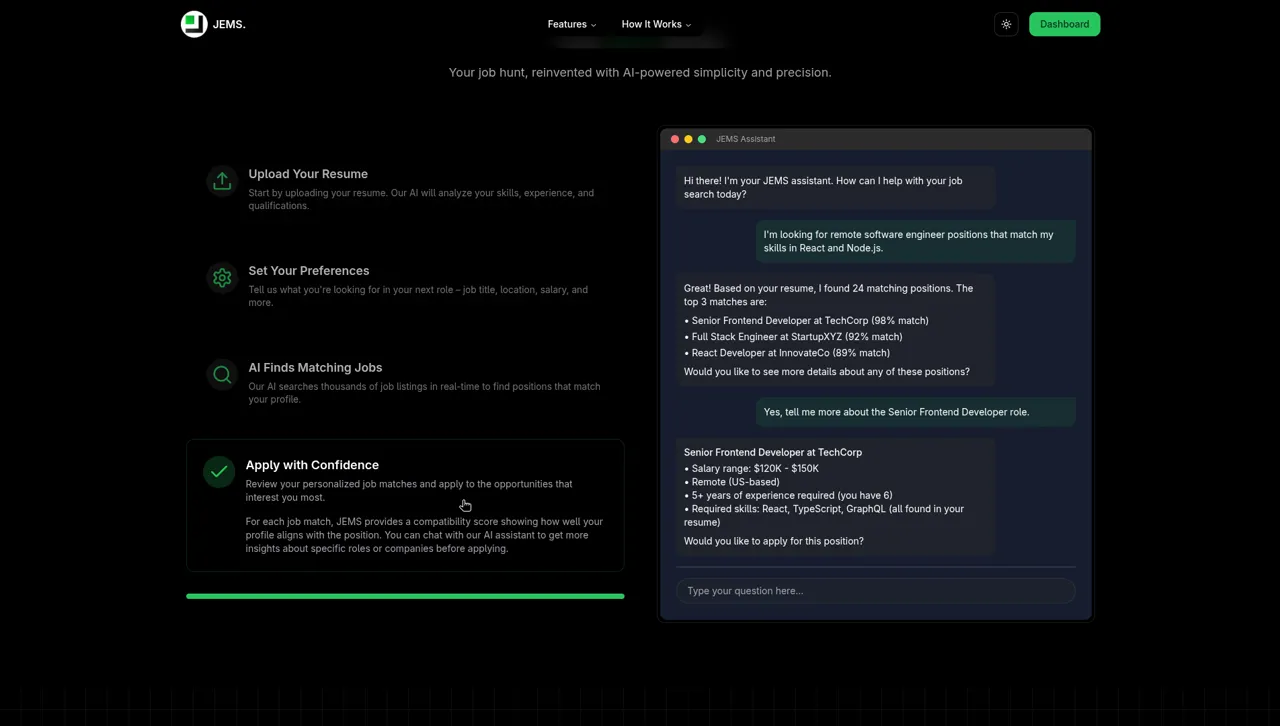
JEMS started as a personal problem: job searching is broken. You spend hours manually filtering irrelevant listings, tailoring resumes, and cold-applying into silence. I wanted to build the intelligent layer that should sit between candidates and job boards — one that understands semantic meaning, not just keyword overlap.
The system is split into two services: a Python FastAPI backend (jems-api-server) handling scraping, embedding generation, and async task orchestration, and a Next.js 14 frontend (jems-next) providing the AI chat interface, resume management, and job dashboard with Better Auth session management.
System Architecture
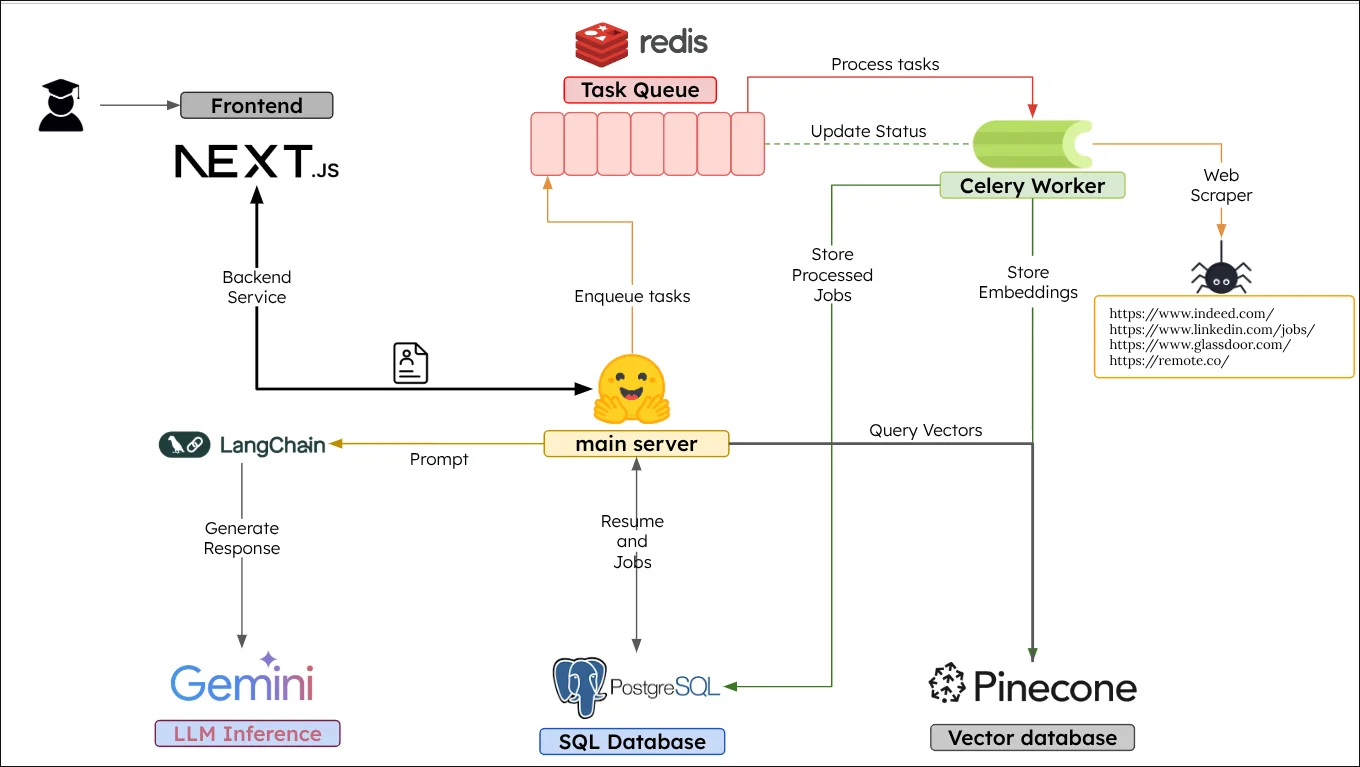
AI Chat & Vector Retrieval Pipeline
The Embedding Engine: all-MiniLM-L6-v2
The core of the matching system. Every job description ingested by the Celery worker is encoded into a 384-dimensional float vector using the sentence-transformers/all-MiniLM-L6-v2 model. This model was chosen specifically because it balances semantic accuracy with low inference latency — critical when processing batches of scraped jobs at scale.
The encoding endpoint is a dedicated FastAPI route that loads the model once at module level (singleton pattern), avoiding per-request model loading overhead:
# app/api/encode.py
from sentence_transformers import SentenceTransformer
from app.core.config import settings
model = SentenceTransformer(settings.EMBEDDING_MODEL) # Loaded once, shared across requests
@router.post("/text", response_model=EncodeResponse)
async def generate_embedding(request: EncodeRequest):
embedding = model.encode(request.text).tolist()
return {"embedding": embedding}The same endpoint is called from the Next.js frontend's getEmbedding() function to convert the user's chat query into the same vector space before the Pinecone ANN search — ensuring apples-to-apples semantic comparison.
Async Task Orchestration: Celery + Upstash Redis
Job scraping is intentionally decoupled from the HTTP request cycle. When the frontend calls POST /api/task/create, the FastAPI route does not scrape — it enqueues a process_job_task payload into Redis via Celery's .delay() method and immediately returns a task_id.
# scripts/enqueue_task.py
def enqueue_task(job_title, location, country, num_jobs, site_names):
task_data = {
"request_id": str(uuid4()),
"task_type": "SCRAPE_AND_EMBED_JOB",
"parameters": {
"job_title": job_title,
"location": location,
"country": country,
"num_jobs": num_jobs,
"site_name": site_names
},
"metadata": {
"user_id": "system_test",
"request_timestamp": datetime.utcnow().isoformat()
}
}
result = process_task.delay(task_data) # Non-blocking dispatch
return result.idThe Celery broker and result backend both use Upstash Redis over SSL (rediss://). Two separate SSL configurations are required — ssl.CERT_REQUIRED for the result backend (strict certificate validation) and a custom cert path via certifi.where() for the broker connection. On worker startup, a @worker_ready signal initializes the PostgreSQL connection pool before any task processing begins.
BetterAuth: Multi-Provider Auth with Organization Support
Authentication is handled by better-auth (not NextAuth), configured with an unusually rich plugin stack. The combination of organization, twoFactor, passkey, admin, multiSession, oneTap, oAuthProxy, openAPI, and oidcProvider means JEMS can serve as an identity provider itself via OIDC, supports hardware security keys via WebAuthn passkeys, and allows multiple concurrent sessions per user.
The nextCookies() plugin integrates session cookies directly into Next.js's cookie system, and middleware.ts uses getSessionCookie() to protect the /onboarding route without a full database hit on every request.
Email delivery (verification, password reset, 2FA OTP, org invitations) routes through Resend with React Email templates — not raw HTML strings.
Pinecone Two-Step Retrieval Pattern
A critical architectural detail: Pinecone stores only { title, company, location, url } as metadata alongside the 384-dim vector. The full job description and raw scraped JSON are stored in Neon PostgreSQL. The retrieval is always a two-step operation:
- ANN search → Pinecone returns
topK=50vector matches with their metadata URLs - Hydration → Those URLs are used as the primary key to
SELECTfull records from theraw_jobstable, includingdescription,source_site, and theraw_data JSONBcolumn
This design keeps Pinecone indexes lean and avoids Pinecone's metadata size limits, while the relational store handles the full structured payload needed by the AI prompt builder.