Scaling a Fault-Tolerant LLM Translation Pipeline on Zero Budget

At BabyCloud, localization was our greatest growth driver—and our greatest budget threat. To localize over 100,000 developmental activities, bedtime stories, and pediatric recipes into regional Indian languages (Hindi, Marathi, Telugu, Tamil, and Bengali), commercial translation API quotes came in at over $15,000. For a pre-seed startup, that was out of the question.
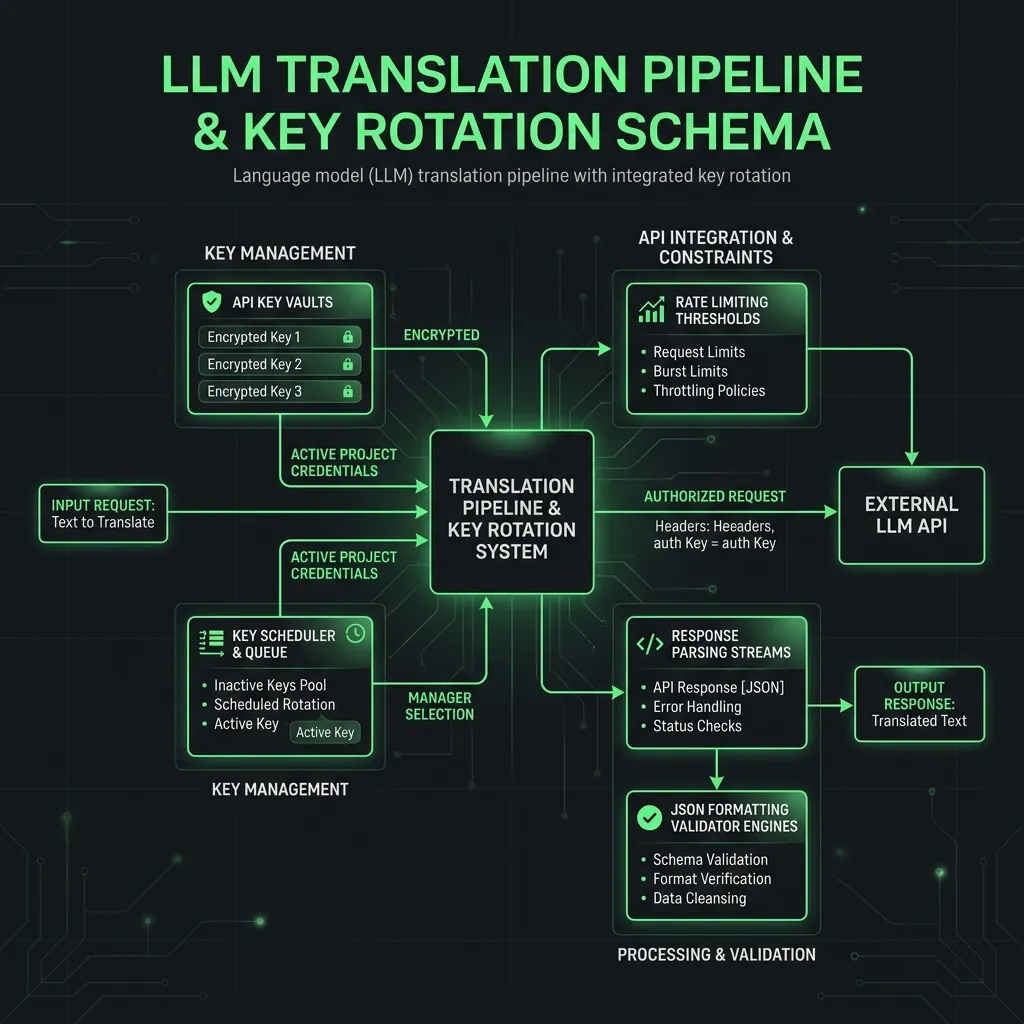
We decided to build an automated translation engine using the Gemini API's free tier. But free tiers come with a catch: a strict limit of 15 Requests Per Minute (RPM) per project, and unpredictable truncation errors where the model cuts off text mid-response.
To overcome these constraints, we scaled the system to run 23 parallel API pipelines by rotating keys across 23 Google Cloud projects, and wrote a custom state-machine JSON-repair parser to catch and rebuild corrupted outputs.
Here is how we built it.
Sharding Concurrency Across 23 GCP Projects
If you try to hit a single free-tier Gemini API key with parallel worker threads, you will hit rate limits within seconds. To work around this, we set up 23 separate GCP projects, generated a unique API key for each, and implemented a sliding-window lock manager.
This lock manager rotates the active key in real time, tracking the timestamp of every request to ensure no single key exceeds the 15 RPM limit.
interface RequestLog {
timestamp: number;
}
export class KeyRateLimiter {
private requestHistory: Map<string, RequestLog[]> = new Map();
private maxRequests: number = 15;
private windowSizeMs: number = 60000; // 1 minute sliding window
public async acquireLock(apiKey: string): Promise<boolean> {
const now = Date.now();
const logs = this.requestHistory.get(apiKey) || [];
// Filter out requests older than the sliding window
const activeLogs = logs.filter(log => now - log.timestamp < this.windowSizeMs);
this.requestHistory.set(apiKey, activeLogs);
if (activeLogs.length >= this.maxRequests) {
return false; // Limit reached for this key
}
activeLogs.push({ timestamp: now });
return true;
}
}Rebuilding Truncated JSON Payloads
Because translating thousands of items at once is expensive, we batched requests. But large batches often triggered response truncation when the LLM hit token output limits mid-generation. When this happened, the API returned broken JSON—missing closing objects, arrays, and quotes—which crashed the default JSON.parse() parser.
Instead of discarding these partial translations and wasting tokens, we wrote a character-by-character state-machine parser. This parser tracks whether the cursor is inside a string block or escaping a character, collects unclosed brackets using a LIFO stack, and dynamically appends the correct closing tokens to recover the valid portion of the JSON payload.
export function repairTruncatedJSON(rawJson: string): string {
let cleaned = rawJson.trim();
// Remove markdown codeblock wrappers if present
cleaned = cleaned.replace(/^```json\s*/i, '').replace(/```$/, '').trim();
const bracketStack: string[] = [];
let inString = false;
let escapeNext = false;
let repaired = '';
for (let i = 0; i < cleaned.length; i++) {
const char = cleaned[i];
if (escapeNext) {
repaired += char;
escapeNext = false;
continue;
}
if (char === '\\') {
repaired += char;
escapeNext = true;
continue;
}
if (char === '"') {
inString = !inString;
repaired += char;
continue;
}
if (!inString) {
if (char === '{' || char === '[') {
bracketStack.push(char);
} else if (char === '}') {
if (bracketStack[bracketStack.length - 1] === '{') {
bracketStack.pop();
}
} else if (char === ']') {
if (bracketStack[bracketStack.length - 1] === '[') {
bracketStack.pop();
}
}
}
repaired += char;
}
// If the cursor was cut off inside a string value, close the quote
if (inString) {
repaired += '"';
}
// Pop and append closing brackets in reverse order (LIFO)
while (bracketStack.length > 0) {
const unclosed = bracketStack.pop();
repaired = repaired.trim();
if (repaired.endsWith(',')) {
repaired = repaired.slice(0, -1);
}
if (unclosed === '{') {
repaired += '}';
} else if (unclosed === '[') {
repaired += ']';
}
}
return repaired;
}Token Optimization Practices
We also needed to keep the context sizes small to stay within free-tier limits. Before sending nested payloads to the LLM, we stripped out metadata keys (like ObjectIds, timestamps, and database index flags) which did not need translation. We wrote a recursive utility to filter out these fields:
export function pruneTranslateTree(obj: any): any {
if (obj === null || typeof obj !== 'object') {
return obj;
}
if (Array.isArray(obj)) {
return obj.map(pruneTranslateTree);
}
const pruned: Record<string, any> = {};
// Define metadata keys to strip before parsing
const blacklistedKeys = ['_id', 'createdAt', 'updatedAt', 'userId', 'status', '__v'];
for (const [key, value] of Object.entries(obj)) {
if (blacklistedKeys.includes(key)) {
continue;
}
// Only translate string fields or recurse into nested structures
if (typeof value === 'string' || typeof value === 'object') {
pruned[key] = pruneTranslateTree(value);
}
}
return pruned;
}Prompt Engineering for JSON Output Reliability
To ensure that the Gemini model returns a parseable structure, we use a system prompt that explicitly restricts output formats. Forcing the model to return structured data is key to preventing parsing errors:
System Prompt Directive: You are a translation microservice. Translate the text fields of the provided JSON payload into the target language. Preserve all key structures. Output ONLY a valid JSON payload. Do not include markdown codeblocks, notes, or descriptions.
Even with this directive, safety filters or network connection lag can still interrupt generations mid-stream. Combining the prompt instructions with our character-by-character recovery stack ensures our pipeline maintains a high success rate even under heavy processing loads.